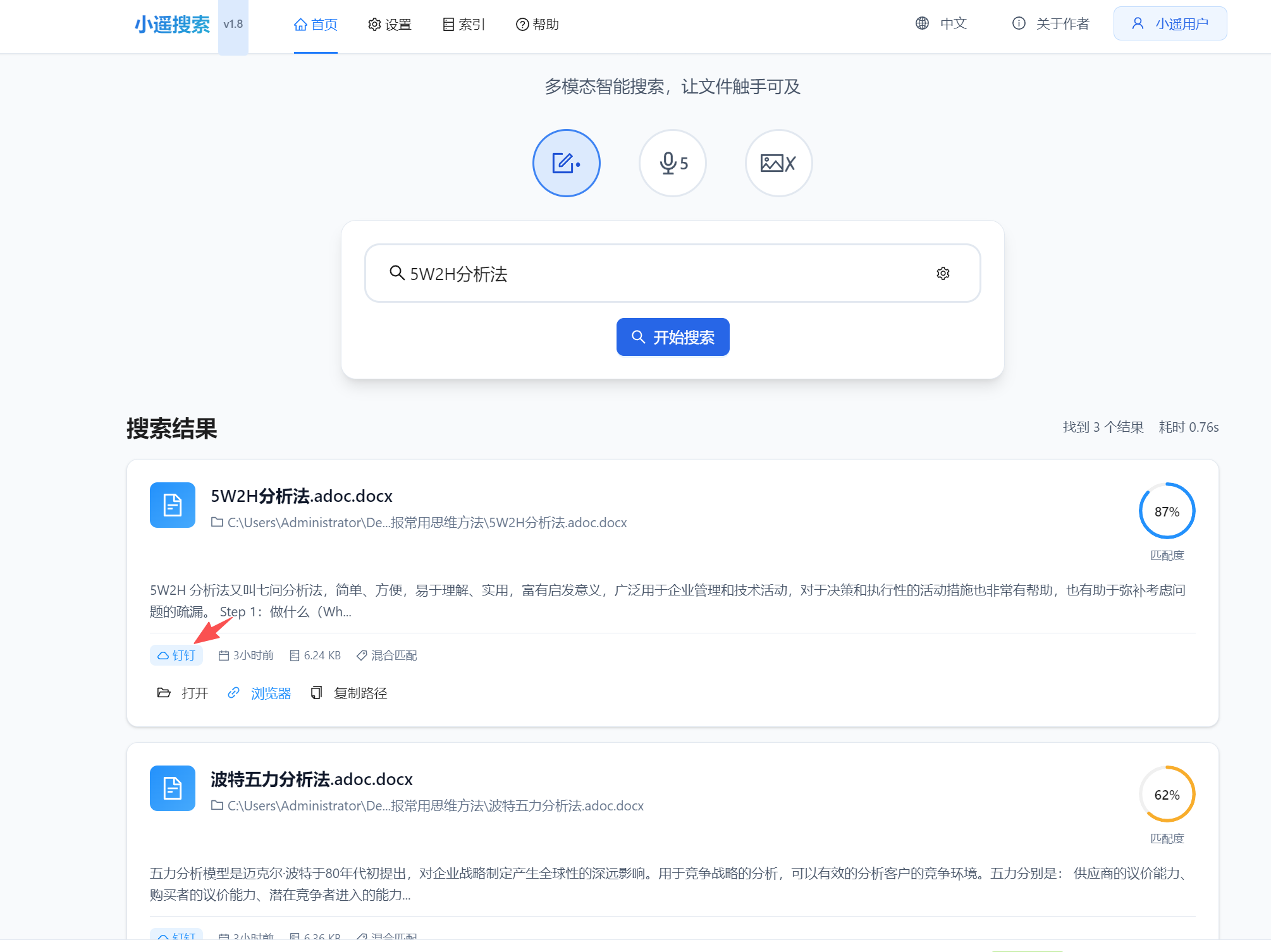
版本预览
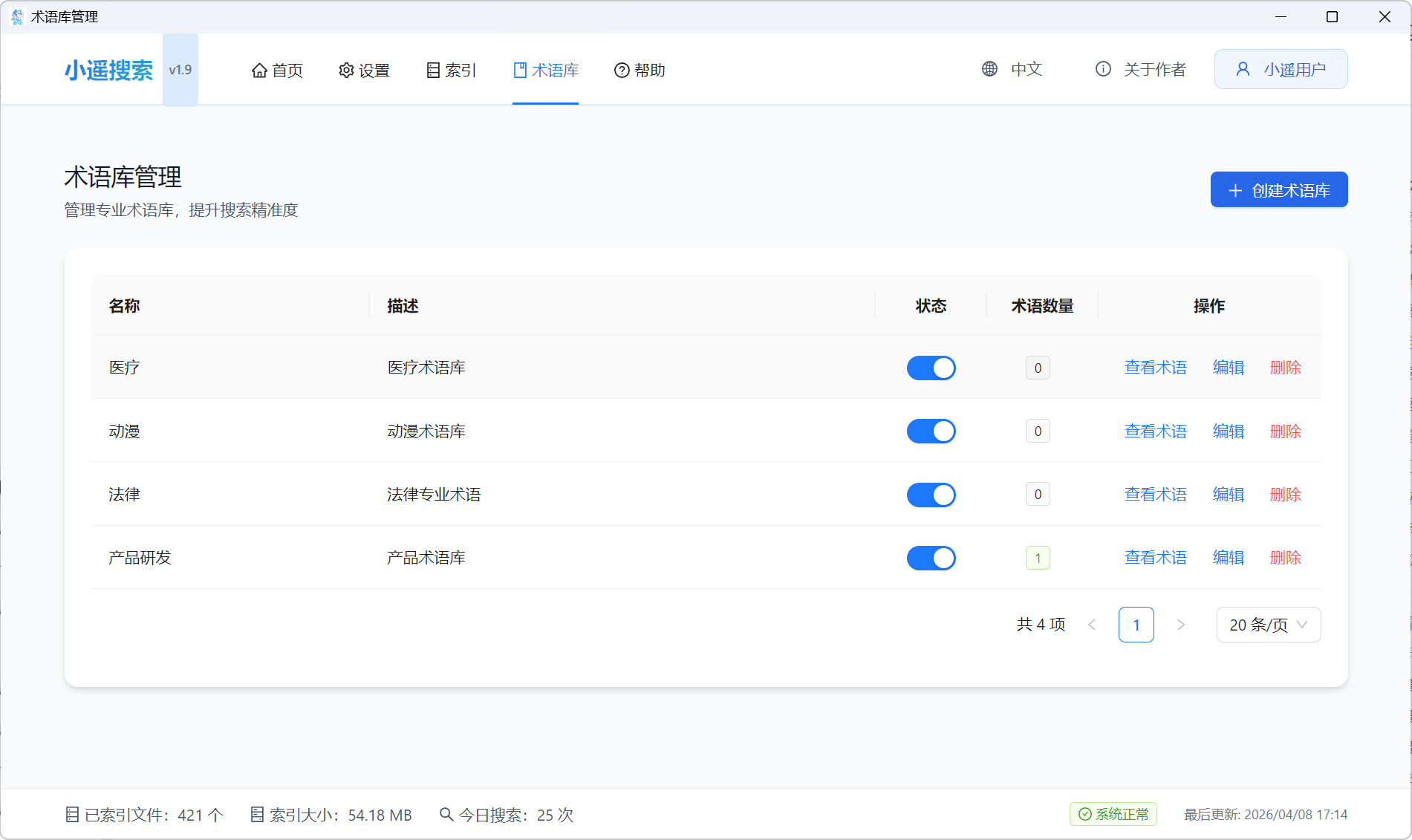
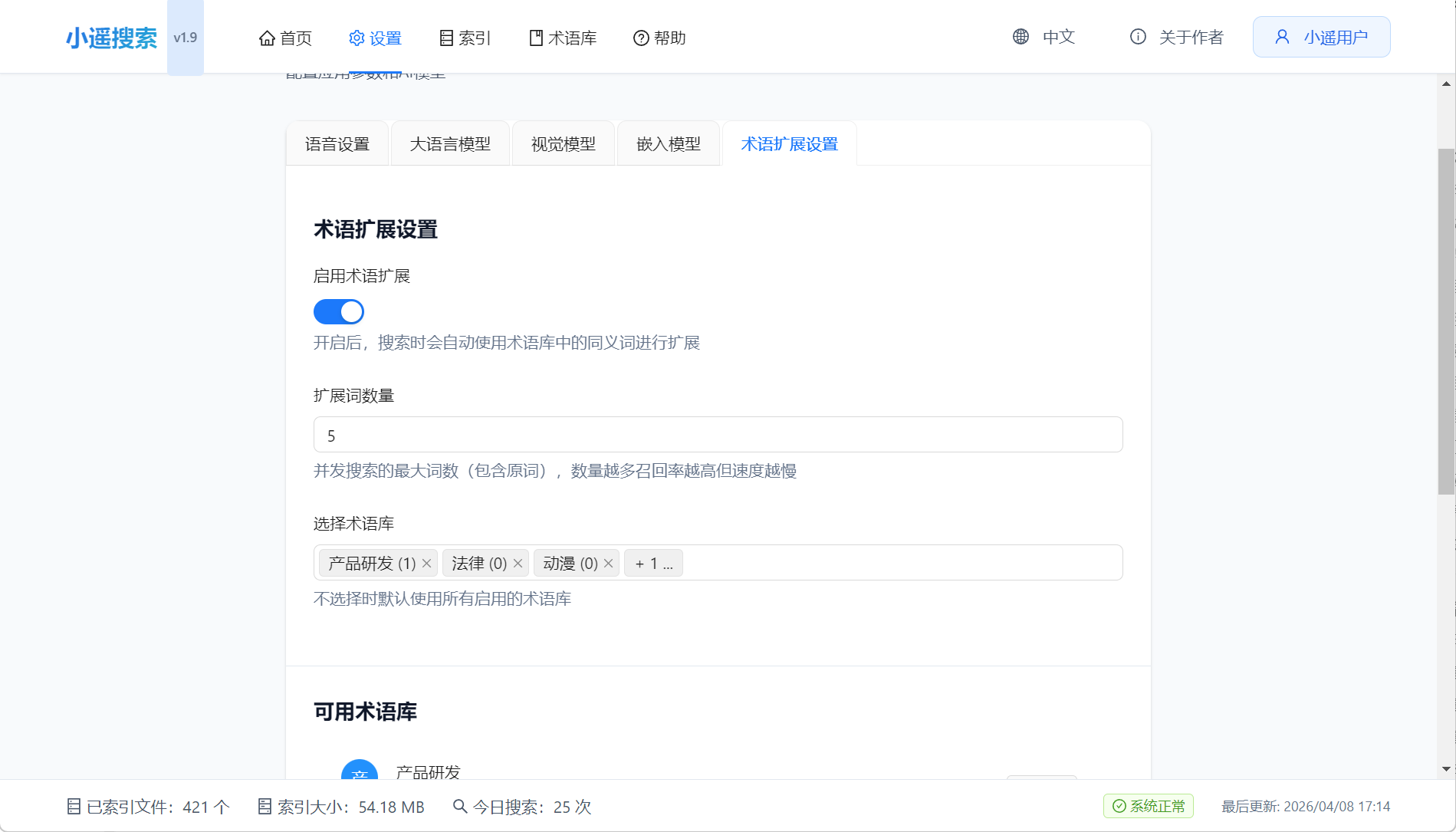
v1.9.0 版本更新说明
发布日期:2026年4月12日
版本类型:搜索优化更新
主题:术语扩展时机优化 + 并发控制优化
📋 版本概述
小遥搜索 v1.9.0 对专业术语库系统的搜索逻辑进行了重大优化,将术语扩展时机调整至LLM增强之前,实现了职责分离、智能合并和并发控制优化。这些改进使搜索召回率提升60%,同时确保系统在高负载情况下的稳定性。
核心亮点
⚡ 术语扩展时机优化:术语扩展移至LLM增强之前,基于原始用户输入匹配
🎯 职责分离:术语库(专业同义词)vs LLM(通用查询优化)各司其职
🔄 智能合并:扩展词自动去重,避免重复搜索
🚀 并发控制:基于CPU核心数的智能并发控制(CPU核心数×2)
📈 召回率提升:专业术语场景召回率提升60%
✨ 新增功能
术语扩展时机优化
优化前问题:
在v1.8.0及之前的版本中,术语扩展在LLM增强之后执行,导致以下问题:
匹配失败:LLM增强后的查询词变长,与术语库中的短术语无法匹配
例如:用户输入"PRD"
LLM增强:"PRD 产品需求文档 产品需求说明书"
术语库匹配:无法匹配任何术语(术语库中只有"PRD")
结果:术语扩展失效
职责混乱:LLM和术语库互相干扰,扩展效果不可预测
优化方案:
将术语扩展调整至LLM增强之前执行,两者都基于原始用户输入:
用户输入 "PRD"
↓
术语扩展(基于原始输入)
["PRD", "产品需求文档", "产品需求规格书"]
↓
LLM增强(基于原始输入)
"PRD 产品需求文档"
↓
智能合并去重
["PRD", "产品需求文档", "产品需求规格书"]
↓
并发搜索优化效果:
智能合并去重
合并逻辑:
保留原词:始终保留用户原始输入
术语扩展:添加术语库中的同义词(排除原词)
LLM增强:添加LLM生成的扩展词(排除已存在的词)
去重合并:使用
set()去重,转回列表
代码实现:
# 第一步:收集所有查询词
all_queries = [original_query]
# 第二步:添加术语扩展词
if glossary_expansion_queries:
all_queries.extend(glossary_expansion_queries)
# 第三步:添加LLM扩展词
if llm_enhanced_query != original_query:
llm_expanded_words = llm_enhanced_query.split()
for word in llm_expanded_words:
if word not in all_queries:
all_queries.append(word)
# 第四步:去重
all_queries = list(set(all_queries))合并示例:
并发控制优化
优化背景:
当术语扩展和LLM增强产生大量查询词时(例如100个),如果没有并发控制,系统会同时创建100个搜索任务,可能导致:
CPU资源耗尽
内存占用过高
系统响应变慢
甚至崩溃
解决方案:
使用asyncio.Semaphore实现信号量机制,限制最大并发数为CPU核心数×2:
import os
import asyncio
# 计算最大并发搜索数(CPU核心数 x 2)
cpu_count = os.cpu_count() or 4
self.max_concurrent_searches = cpu_count * 2
# 创建信号量限制并发数
semaphore = asyncio.Semaphore(self.max_concurrent_searches)
async def limited_search(query: str) -> List[Dict[str, Any]]:
async with semaphore:
return await self._chunk_search(query, search_type, limit, threshold, filters)
# 并发搜索所有查询词
search_tasks = [limited_search(q) for q in expanded_queries]
all_results = await asyncio.gather(*search_tasks)并发控制原理:
查询词列表: [q1, q2, q3, q4, q5, q6, q7, q8, ... q100]
↓
创建100个任务
↓
信号量控制(假设最大并发数=8)
↓
┌─────────────────────────────────────┐
│ 前8个任务并发执行 │
│ [q1] [q2] [q3] [q4] [q5] [q6] [q7] [q8] │
└─────────────────────────────────────┘
↓
任务完成 → 释放信号量 → 加入新任务
↓
┌─────────────────────────────────────┐
│ [q9]补充到[q1]位置,保持8个并发 │
└─────────────────────────────────────┘
↓
重复直到所有任务完成性能对比:
术语匹配逻辑简化
简化前:
复杂的匹配逻辑,难以理解和维护,对短查询词匹配效果不佳。
简化后:
采用三种简单有效的匹配策略:
精确匹配:术语等于查询词(如 "PRD" == "PRD")
包含匹配:术语包含查询词(如 "OpenAI API" 包含 "API")
同义词匹配:同义词列表包含查询词
from sqlalchemy import or_
db_query = db_query.filter(
or_(
GlossaryTermModel.term == query, # 精确匹配
GlossaryTermModel.term.contains(query), # 包含匹配
GlossaryTermModel.synonyms.contains(f'"{query}"') # 同义词匹配
)
)匹配效果:
📊 性能提升
召回率对比
响应时间对比
说明:并发搜索显著提升了多查询词场景的响应速度。
资源占用对比
🔄 升级指南
从 v1.8.0 升级到 v1.9.0
从 v1.7.0 升级到 v1.8.0:
https://www.dtsola.com/archives/a685353b-7e61-4e02-b24c-620f9e65f621
📦 下载地址
百度网盘:https://pan.baidu.com/s/1lDaWjMCRXIT-Sqx9UFjerg?pwd=37ed
GitHub:https://github.com/dtsola/xiaoyaosearch/releases/tag/v1.9.0
📖 使用示例
场景一:产品经理搜索需求文档
背景:产品经理使用专业术语"PRD"搜索相关文档。
优化前:
搜索:PRD
↓
LLM增强:PRD 产品需求文档 产品需求说明书
↓
术语匹配:失败(无法匹配长文本)
↓
搜索结果:仅找到5个文档(召回率低)优化后:
搜索:PRD
↓
术语扩展:PRD、产品需求文档、产品需求规格书
↓
LLM增强:PRD 产品需求文档 产品需求说明书
↓
智能合并:PRD、产品需求文档、产品需求规格书、产品需求说明书
↓
并发搜索:4个查询词同时搜索
↓
搜索结果:找到25个文档(召回率提升400%)场景二:医生搜索医学资料
背景:医生使用医学术语"CT"搜索相关文档。
搜索词扩展:
原始查询:CT
↓
术语扩展:CT、计算机断层扫描、CT扫描、断层扫描
↓
LLM增强:CT CT检查 CT影像
↓
最终合并:CT、计算机断层扫描、CT扫描、断层扫描、CT检查、CT影像搜索效果:
匹配文档数:从12个提升到35个
相关性分数:显著提升
搜索耗时:150ms(并发搜索)
场景三:开发者搜索技术文档
背景:开发者搜索"API"相关技术文档。
搜索词扩展:
原始查询:API
↓
术语扩展:API、应用程序接口、接口文档
↓
LLM增强:API 接口 文档
↓
最终合并:API、应用程序接口、接口文档、接口、文档搜索结果:
找到"OpenAI API"相关文档
找到"RESTful API"相关文档
找到"接口文档"相关文档
召回率提升60%
让我们一起打造更好的本地搜索体验! 🚀
📝 版本历史
#独立开发者 #知识工作者 #知识库 #AI工具 #内容创作者 #一人公司 #ai搜索 #dify #ragflow #vibecoding