版本预览
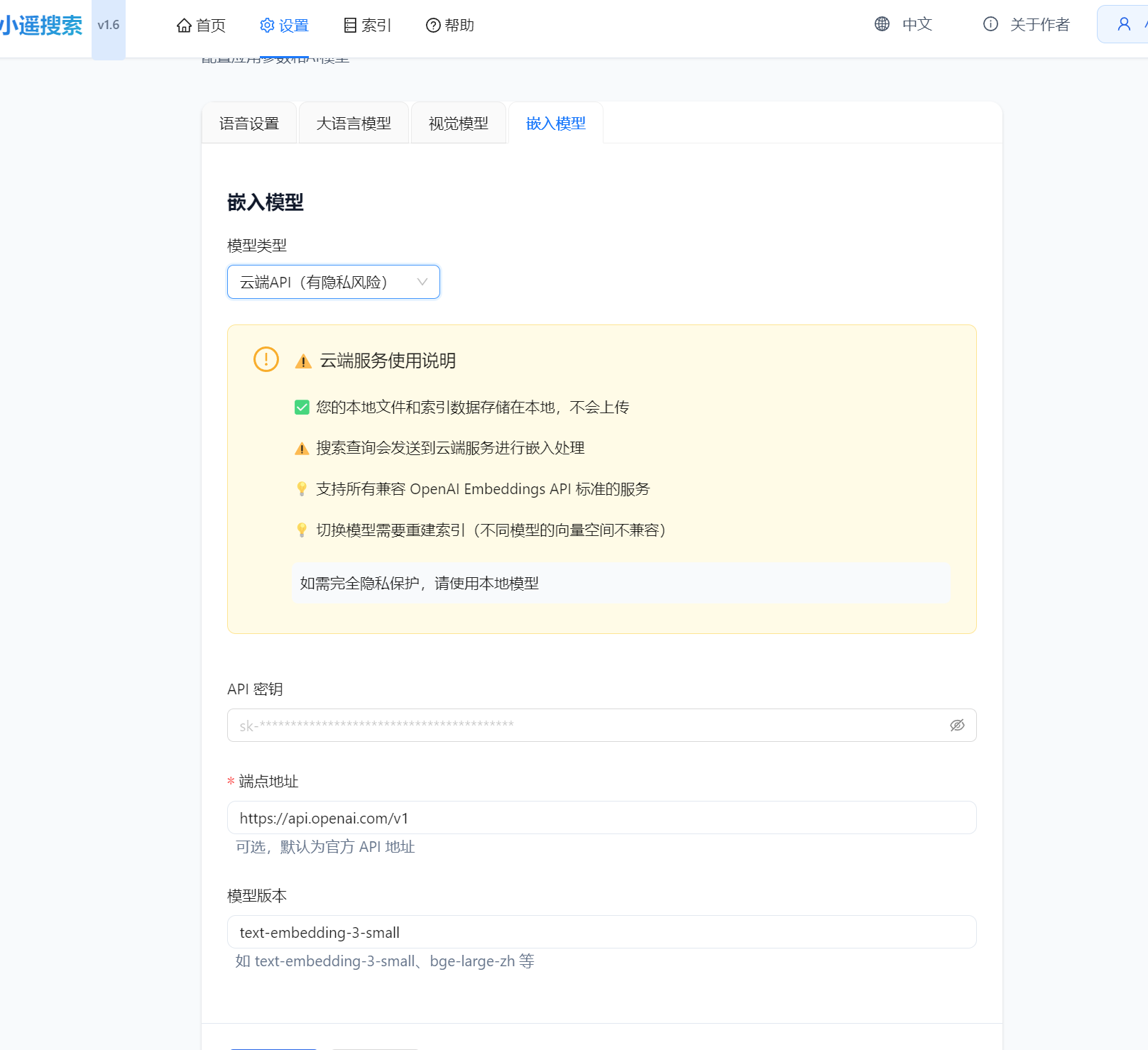
嵌入模型切换
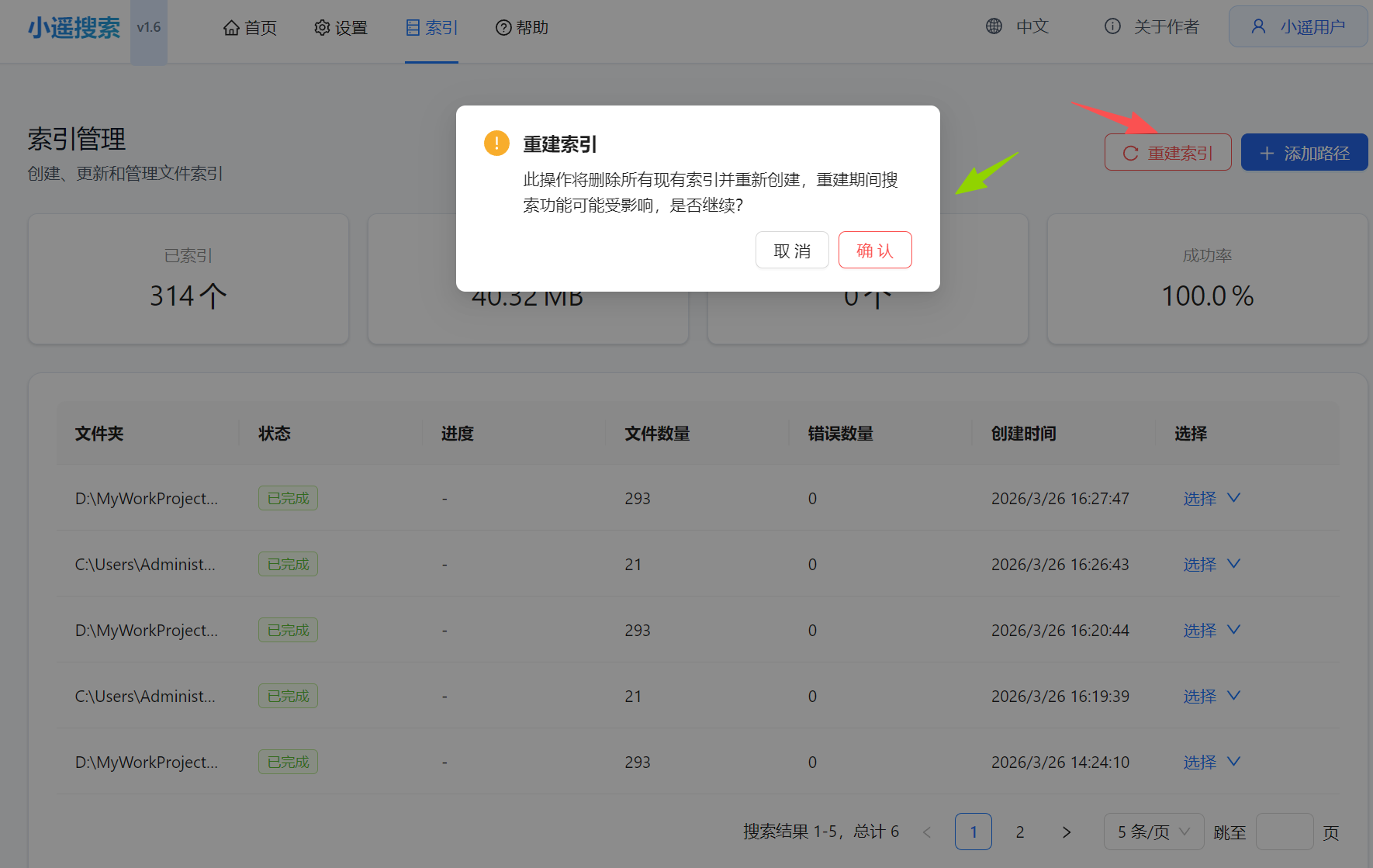
重建索引
v1.6.0 版本更新说明
发布日期:2026年3月30日
版本类型:重大功能更新 + Bug 修复
主题:云端嵌入模型支持 + 搜索质量优化
📋 版本概述
小遥搜索 v1.6.0 正式支持 OpenAI 兼容云端嵌入模型,用户可自由切换本地和云端模型。同时修复了全文搜索在高级嵌入模型下无结果的问题,并优化了混合搜索算法。
核心亮点
☁️ 云端嵌入模型支持:支持 OpenAI、DeepSeek、阿里云等兼容 API
🔄 本地/云端互斥切换:设置页面一键切换,重启生效
🔧 全量重建索引:索引管理页面一键重建所有索引
🐛 Bug 修复:修复全文搜索在高维度嵌入模型下无结果的问题
⚡ 混合搜索优化:调整算法权重,提升搜索准确度
✨ 新增功能
云端嵌入模型支持
支持的云端服务:
模型切换方式:
打开 设置 → 嵌入模型 标签
选择 模型类型:
本地(BGE-M3,推荐):使用本地 BGE-M3 模型
云端API(有隐私风险):使用 OpenAI 兼容 API
配置云端参数(如选择云端):
API 密钥
端点地址(默认官方 API)
模型名称
点击 保存设置
重启应用生效
根据提示前往索引管理页面 重建索引
注意事项:
⚠️ 搜索查询会发送到云端进行处理
✅ 本地文件和索引数据不上传
🔒 切换模型需要重建索引(向量空间不兼容)
全量重建索引功能
重建索引入口:
打开 索引管理 页面
点击红色 "重建索引" 按钮(在"添加路径"按钮左侧)
确认后系统将:
清空所有现有索引
查询历史已完成的索引任务
按文件夹路径去重
自动创建重建任务并排队处理
重建进度:
重建期间可正常使用旧索引进行搜索
实时显示重建进度(百分比、已处理/总文件数)
支持同时重建多个文件夹路径
🐛 Bug 修复
修复:全文搜索在高维嵌入模型下无结果
问题描述:
使用更高维度的云端嵌入模型(如 1536 维的 text-embedding-3-large)时,全文搜索返回空结果。
根本原因:
原代码中全文搜索的阈值设置过高(0.5),对于高维向量空间中的文本匹配过于严格。
修复方案:
调整全文搜索的阈值逻辑,对不同嵌入模型维度使用不同的阈值策略:
修复文件:
backend/app/services/search_service.py
优化:混合搜索算法调整
问题描述:
原混合搜索算法对语义搜索和全文搜索的权重分配过于简单,导致搜索结果不够准确。
优化方案:
动态权重调整:根据查询类型自动调整权重
分数归一化:将语义搜索分数和全文搜索分数归一化到 [0, 1] 区间
相关性增强:优先返回两种搜索都匹配的结果
优化效果:
优化文件:
backend/app/services/search_service.py
📚 技术实现
云端嵌入服务架构
技术栈:
aiohttp- 异步 HTTP 客户端Pydantic- 数据验证tenacity- 自动重试机制
核心特性:
# 自动重试配置
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=2, max=10)
)
async def _call_embeddings_api(self, texts: List[str]):
# API 调用逻辑批处理优化:
默认批次大小:32(云端 API 限制)
自动调整:根据内容长度动态调整
错误恢复:批次失败时使用零向量填充
索引重建机制
简化实现方案:
复用现有 IndexJob 任务系统和 run_full_index_task 后台任务:
清空索引:删除所有 Faiss 索引文件和 Whoosh 索引目录
查询历史任务:查找已完成的索引任务,按
folder_path去重创建新任务:为每个唯一路径创建新的
IndexJob记录后台处理:利用 FastAPI
BackgroundTasks自动排队处理
技术优势:
无需独立的重建服务,降低复杂度
复用现有任务流程,减少代码量
自动排队,支持多路径重建
🔄 版本升级指南
https://www.dtsola.com/archives/a685353b-7e61-4e02-b24c-620f9e65f621
📦 下载地址
百度网盘:https://pan.baidu.com/s/1lDaWjMCRXIT-Sqx9UFjerg?pwd=37ed
GitHub:https://github.com/dtsola/xiaoyaosearch/releases/tag/v1.6.0
🙏 致谢
感谢以下开源项目的支持:
OpenAI API - 嵌入模型 API
aiohttp - 异步 HTTP 客户端
tenacity - Python 重试库
让我们一起打造更好的本地搜索体验! 🚀
#独立开发者 #知识工作者 #知识库 #AI工具 #内容创作者 #一人公司 #ai搜索 #dify #ragflow #vibecoding