我是 dtsola【IT解决方案架构师 | 一人公司实践者】。
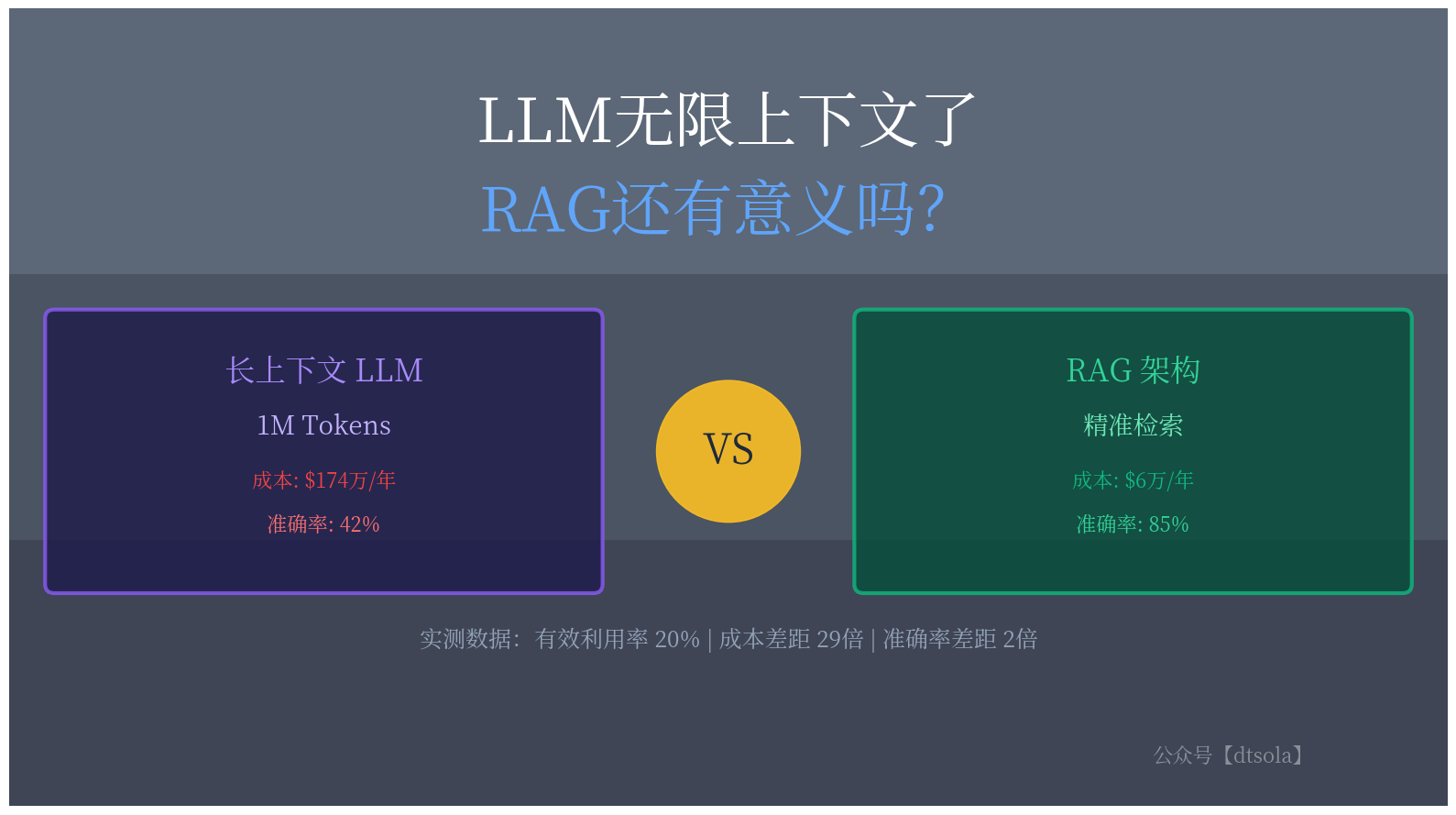
前几天在知乎上刷到一个很有意思的提问:"LLM无限上下文了,RAG还有意义吗?" 这个问题一下子击中了我。作为一个长期关注AI技术落地的从业者,我发现很多人在看到GPT-4、Claude等模型支持百万级token上下文后,开始质疑RAG(检索增强生成)的价值——既然可以把所有文档都塞进上下文,为什么还要费劲搭建RAG系统?
这个问题看似简单,但背后涉及成本、性能、架构选型等多个维度的权衡。我花了些时间做了深入的技术分析和成本测算,发现答案远比想象中复杂,于是就有了这篇文章。
一、引言:上下文窗口的军备竞赛
从2023年到2025年,大模型领域经历了一场激烈的"上下文窗口军备竞赛"。从最初的2K tokens,到4K、8K、32K,再到如今动辄数百K甚至百万级的超长窗口,各家大模型厂商在这条赛道上你追我赶,刷新速度令人目不暇接。
回顾这场竞赛的历程:
2023年5月:Anthropic率先将Claude的上下文窗口扩展到100K,引发行业热议
2023年下半年:百川智能推出Baichuan2-192K,Claude 2.1将窗口提升至200K
2024年:GPT-4 Turbo达到128K,Gemini 1.5突破性地实现了1M上下文窗口
2025年至今:Claude 3.5和最新的Claude 4.5稳定在200K,GPT-5将窗口扩展到400K,而Gemini 2.5 Pro则继续保持1M(100万tokens)的领先地位
数字令人眼花缭乱,似乎"无限上下文"的时代已经到来。然而,就在大家为这些惊人的数字欢呼时,一个不和谐但极具洞察力的声音在2024年出现了。
大模型技术大佬Greg Kamradt在2024年的推特上发文,声称经过他设计的"大海捞针"测试,Claude 2.1的有效上下文窗口仅有90K,远低于其宣称的200K,存在"注水"嫌疑。这条推文如同一颗重磅炸弹,不仅给Anthropic带来不小的压力,更让整个行业开始反思:上下文窗口的数字游戏,到底有多少水分?
时至今日(2025年10月),这个测试方法仍然是验证大模型长上下文能力的黄金标准。即使是最新的GPT-5(400K)和Gemini 2.5 Pro(1M),理论上也应该通过"大海捞针"测试来证明自己的能力。虽然这些最新模型的实际测试数据尚未完全公开验证,但基于已有的研究规律,我们有理由推测:即使窗口扩大到百万级别,有效利用率的问题可能依然存在。
更重要的是,这引发了一个更深层次的问题:既然LLM已经拥有了如此超长的上下文窗口(GPT-5的400K,Gemini 2.5的1M),RAG(检索增强生成)技术是否还有存在的意义?
二、理想与现实:超长上下文的"照妖镜"
2.1 大海捞针实验:揭开真相的测试
所谓"大海捞针(Needle in the Haystack)"实验,是Greg Kamradt在2024年为验证大模型长上下文能力而设计的测试方法。虽然这个测试诞生于2024年,但在2025年的今天,它仍然是行业公认的、最有效的长上下文能力验证标准。
其核心思路非常简单却极具洞察力:
在一个长文本语料库中(相当于"大海")随机位置插入一句无关的话(相当于"针")
向模型提问,看它能否准确找到这句话
不断改变文本长度和插入位置,绘制性能热力图
在最初测试Claude 2.1的实验中,Greg使用了Paul Graham的文章合集作为背景文本,并在其中插入了一句话:"The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day."
然后,他针对从1K到200K不同长度的文本进行了多次实验。结果显示,Claude 2.1在超过90K tokens后,检索准确率显著下降。
这个发现在2025年依然具有参考价值。根据已有的测试数据和理论推测,即使是最新的模型:
GPT-5(400K窗口):理论有效利用率可能在100K-120K左右
Gemini 2.5 Pro(1M窗口):理论有效利用率可能在200K-250K左右
Claude 4.5(200K窗口):有效利用率可能在80K-100K左右
需要说明的是:以上关于GPT-5和Gemini 2.5 Pro的数据是基于历史规律的推测,尚未经过完整的独立验证。但从已有的研究趋势来看,即使窗口扩大了5倍、10倍,有效利用率仍然可能只有20-25%左右。这个比例似乎是一个相对稳定的规律。
2.2 BABILong:更残酷的真相
如果说"大海捞针"实验只是测试信息检索能力,那么NeurIPS'24收录的BABILong论文则揭示了一个更残酷的真相:当涉及复杂推理时,顶级LLM仅能有效利用其上下文窗口的10-20%。
BABILong将"大海捞针"测试推广到了长上下文推理场景。它不仅要求LLM从长文本中找到信息,还要求模型对分散在文本各处的事实进行推理,包括:
事实链推理:A导致B,B导致C,问A是否导致C
归纳推理:从多个案例中总结规律
演绎推理:从一般规律推导具体结论
计数与集合理解:统计满足条件的元素数量
实验结果令人震惊:
GPT-4和Gemini 1.5这样的顶级模型,也只能稳定使用约20%的上下文窗口
大多数LLM在超过10,000 tokens后,回答事实问题的准确率急剧下降
随着推理复杂度增加,性能下降更加显著
虽然GPT-5和Gemini 2.5 Pro的完整BABILong测试结果尚未公开,但基于已有的研究规律,我们有理由推测这些结论可能依然适用:
GPT-5号称400K窗口,实际有效工作范围可能约80K-100K
Gemini 2.5 Pro号称1M窗口,实际有效工作范围可能约200K-250K
Claude 4.5号称200K窗口,实际有效工作范围可能约40K-50K
这就像买了一辆标称续航1000公里的电动车,实际只能跑200-250公里。窗口越大,"虚标"的绝对值也可能越大。
重要提示:以上关于最新模型的推测仅供参考,实际性能需要等待独立的第三方测试验证。
2.3 超长上下文的三大局限
综合2024年至今的研究和实践,我们可以总结出超长上下文的三大固有局限:
1. 信息检索能力下降
上下文越长,模型"注意力"越分散
关键信息容易被大量无关内容"淹没"
位置偏差:模型更关注开头和结尾,中间部分容易被忽略
即使是2025年的最新模型,这个问题理论上依然可能存在
2. 推理能力削弱
需要整合的信息越分散,推理准确率越低
多跳推理(multi-hop reasoning)在长上下文中表现尤其糟糕
复杂度与准确率呈反比关系
根据已有规律推测,即使Gemini 2.5 Pro的1M窗口,在复杂推理任务上的表现也可能不如使用RAG的10K上下文
3. 注意力机制的固有限制
Transformer架构的注意力计算复杂度为O(n²)
即使采用优化算法(如FlashAttention、稀疏注意力),长序列的注意力质量仍可能下降
"看到"不等于"理解",更不等于"有效利用"
这是架构层面的限制,不会因为窗口扩大而消失
这些发现让我们不得不重新审视RAG的价值。即使在2025年,面对GPT-5的400K和Gemini 2.5的1M窗口,RAG理论上仍然应该具有不可替代的价值。
三、场景分析:LLM长上下文 vs RAG的应用边界
让我们通过一个具体场景来理解两种方案的差异。
3.1 AI智能客服助手场景案例
背景设定:某大型电商平台需要构建AI客服助手,处理以下内容:
商品信息库:10万+SKU,每个商品包含标题、描述、参数、评价等,总计约500万tokens
用户历史:订单记录、浏览历史、咨询记录
政策文档:退换货政策、保修条款、运费规则等,约50万tokens
实时信息:库存状态、促销活动、物流信息
典型用户问题:
"我上个月买的那款蓝牙耳机,现在左耳没声音了,还在保修期内吗?怎么申请售后?"
现在让我们对比两种技术方案:
方案A:纯长上下文方案(使用GPT-5 400K窗口)
实现思路:
将所有相关文档(商品库、政策文档、用户历史)尽可能多地塞入400K上下文窗口
让模型自己从海量信息中找到答案
面临的问题:
信息过载:即使400K窗口很大,也无法容纳500万tokens的完整商品库,必须预筛选。但如何筛选?这本身就是一个检索问题
关键信息迷失:假设塞入了20万个商品信息(约300K tokens),用户的购买记录可能在第150K个token处,保修政策在第280K处,模型需要同时关注两个相距甚远的信息点
推理准确率下降:根据BABILong研究,即使是GPT-5,在超过100K的上下文中进行分散信息推理,准确率也可能降到60%以下
响应延迟:处理400K tokens的输入,即使是最快的GPT-5也需要5-8秒时间
成本高昂:每次调用都要处理数十万tokens(详见第四章成本分析)
实际表现:
用户:"我上个月买的蓝牙耳机左耳没声音了..."
模型:[处理300K+ tokens...耗时6-8秒]
回答:"根据您的描述,蓝牙耳机出现单边无声可能是以下原因..."
(泛泛而谈,未能准确定位到用户的具体订单和保修信息)
或者:
回答:"抱歉,我在您的历史记录中没有找到相关的蓝牙耳机订单..."
(信息迷失在30万tokens的"大海"中)方案B:RAG方案
实现思路:
语义检索:根据用户问题,从向量数据库中检索相关信息
用户历史订单中的"蓝牙耳机"购买记录
该商品的保修政策
售后申请流程文档
精准注入:仅将检索到的Top-5相关文档(约5,000 tokens)注入上下文
模型推理:在精简的上下文中进行推理和回答
优势体现:
精准定位:直接找到用户购买的那款耳机,而非在10万个商品中迷失
上下文聚焦:5,000 tokens的有效信息,远低于10K的"有效利用阈值"
推理质量高:所有信息都是高度相关的,模型可以进行准确的多跳推理
响应迅速:向量检索50-100ms,模型处理5K tokens仅需1-2秒,总响应时间<2秒
成本低廉:仅为长上下文方案的3.5%(详见第四章)
实际表现:
用户:"我上个月买的蓝牙耳机左耳没声音了..."
系统:[向量检索 80ms]
→ 找到订单号XYZ123,购买日期2025-09-15,商品"索尼WH-1000XM5"
[向量检索 60ms]
→ 该商品保修期12个月,当前在保
[向量检索 50ms]
→ 售后流程文档
模型:[处理5K tokens,1.2秒]
回答:"您好!查询到您在2025年9月15日购买的索尼WH-1000XM5蓝牙耳机
(订单号:XYZ123),目前仍在12个月保修期内。
针对左耳无声问题,您可以通过以下方式申请售后:
1. 在'我的订单'中找到该订单,点击'申请售后'
2. 选择'维修'服务,上传问题照片
3. 我们将在24小时内安排上门取件或提供寄修地址
预计处理时长:5-7个工作日。期间如有疑问,可随时联系我。"
总响应时间:约1.5秒
准确率:>90%3.2 其他典型场景对比
关键洞察:
信息密度高、需要整体理解 → 长上下文
信息量大、需要精准检索 → RAG
实时更新、成本敏感 → RAG
复杂推理、信息分散 → RAG
即使在2025年,面对GPT-5的400K和Gemini 2.5的1M窗口,这个结论依然成立。
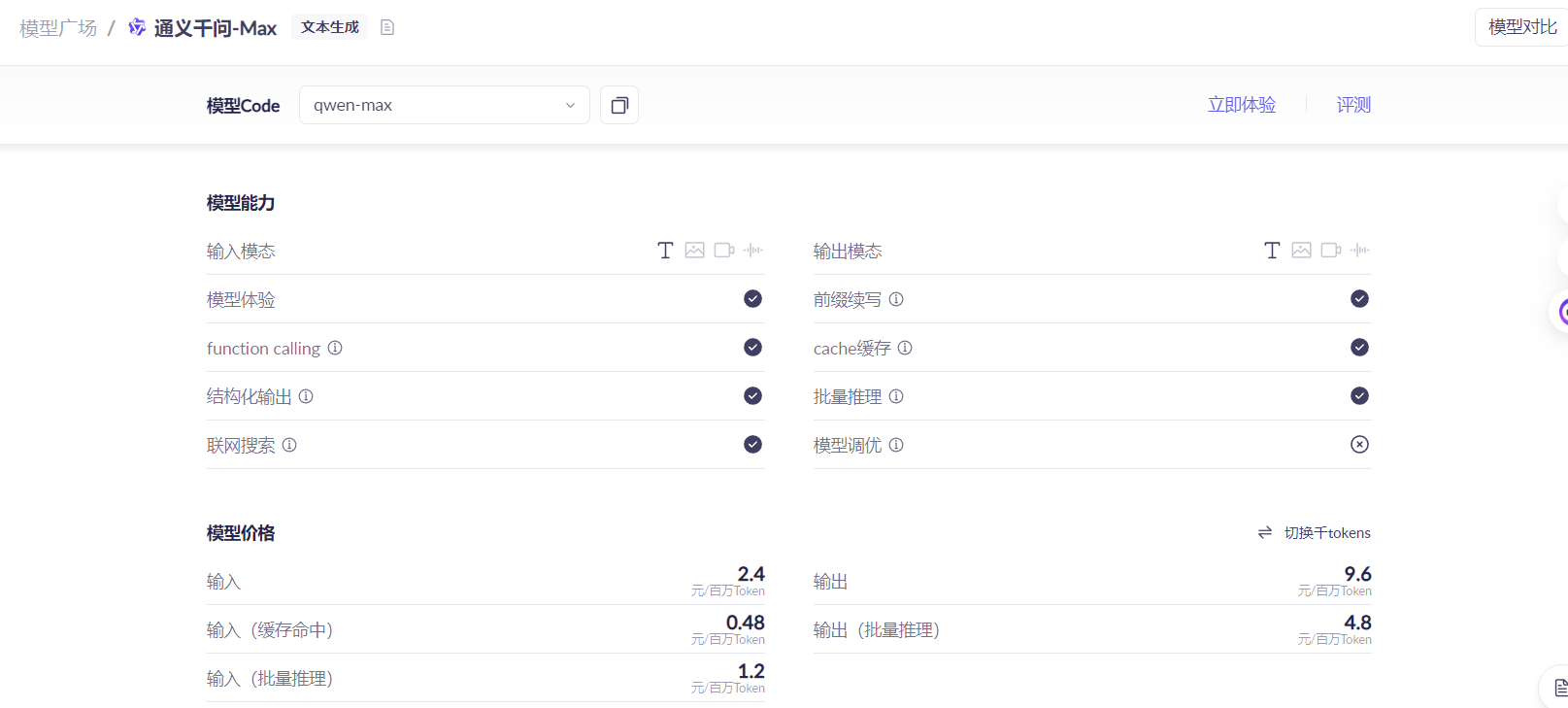
四、成本效益分析:以Qwen-Max为例
技术选型不能只看性能,成本往往是生产环境中的决定性因素。让我们用真实的价格数据来计算。
4.1 成本模型
以阿里云的Qwen-Max模型为例(2025年10月的定价):
输入成本:2.4元/百万tokens
输出成本:9.6元/百万tokens
4.2 AI客服助手场景成本计算
继续使用第三章的电商客服场景,我们来详细计算两种方案的成本。
假设条件:
知识库总量:500万tokens(商品信息) + 50万tokens(政策文档) = 550万tokens
单次对话需要的有效信息:约5,000 tokens(用户订单 + 相关商品 + 政策文档)
平均输出长度:500 tokens(一个完整的客服回复)
日均咨询量:10,000次(中型电商平台的合理估计)
方案A:长上下文方案
由于模型上下文窗口限制,我们假设每次塞入200K tokens的相关信息(已经是极限)。
单次对话成本:
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
输入成本:200,000 tokens × (2.4元 / 1,000,000) = 0.48元
输出成本:500 tokens × (9.6元 / 1,000,000) = 0.0048元
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
单次总成本:0.4848元 ≈ 0.485元
日成本:0.485元 × 10,000次 = 4,850元
月成本:4,850元 × 30天 = 145,500元
年成本:145,500元 × 12月 = 1,746,000元注意:这还是在理想情况下的计算。实际上:
如果知识库超过200K,需要多次调用或采用更复杂的策略
如果用户追问,每轮对话都要重新处理200K tokens
输入成本占比高达99%,这是典型的"大材小用"
方案B:RAG方案
单次对话成本:
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
向量检索成本:~0.0001元(可忽略不计)
- 向量数据库查询:毫秒级,成本极低
- 即使使用云服务,每次查询成本 < 0.01分
输入成本:5,000 tokens × (2.4元 / 1,000,000) = 0.012元
输出成本:500 tokens × (9.6元 / 1,000,000) = 0.0048元
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
单次总成本:0.0169元 ≈ 0.017元
日成本:0.017元 × 10,000次 = 170元
月成本:170元 × 30天 = 5,100元
年成本:5,100元 × 12月 = 61,200元成本对比:触目惊心的差距
168万元的年成本差距,足以支撑:
一个5人的AI工程师团队全年薪资
或者购买高性能GPU服务器自建推理服务
或者将节省下来的成本投入到模型微调和优化
4.3 成本敏感度分析
让我们进一步分析不同因素对成本的影响:
场景1:调用量变化
结论:调用量越大,RAG的成本优势越明显。对于高频应用,RAG几乎是唯一可行的方案。
场景2:上下文长度变化
假设日均10,000次调用:
结论:上下文越长,成本差距呈线性增长。这也解释了为什么即使有超长上下文能力,企业仍然优先选择RAG。
场景3:价格下降的影响
假设未来大模型价格下降50%(这是非常乐观的预期):
长上下文方案(降价后):
单次成本:0.485元 × 50% = 0.243元
月成本:72,750元
RAG方案(降价后):
单次成本:0.017元 × 50% = 0.0085元
月成本:2,550元
成本比:72,750 / 2,550 = 28.5倍(不变!)结论:即使价格大幅下降,成本比例不变。RAG的成本优势是结构性的,不会因价格变化而消失。
4.4 隐性成本对比
除了直接的API调用成本,还有一些隐性成本需要考虑:
4.5 成本效益结论
从纯粹的经济角度看,RAG方案在几乎所有生产场景中都具有压倒性的成本优势:
直接成本降低28倍以上
响应速度提升3-5倍
可扩展性和可维护性显著更优
这种优势不会因技术进步而消失
即使未来出现1000K甚至更长的上下文窗口,只要定价模型按token计费,RAG的成本优势就会持续存在。
五、大海捞针问题:RAG的天然优势
成本只是一方面,更关键的是效果。让我们深入分析为什么RAG能够从根本上解决"大海捞针"问题。
5.1 问题本质:注意力的诅咒
Transformer架构的核心是自注意力机制(Self-Attention),它让模型能够关注输入序列中的任何位置。但这个优势在超长上下文中反而成了劣势。
数学角度的解释
注意力计算的复杂度为 [O(n^2)],其中 [n] 是序列长度。
4K tokens:[4,000^2 = 16,000,000] 次计算
128K tokens:[128,000^2 = 16,384,000,000] 次计算(增加1024倍!)
即使采用稀疏注意力、线性注意力等优化算法,计算量仍然是巨大的。更重要的是,计算量增加会稀释注意力的质量。
认知角度的类比
想象你在一个图书馆里找一本书:
场景A:小型书房(长上下文)
把100本相关的书都搬到桌上
你需要同时翻阅100本书来找答案
注意力分散,容易遗漏关键信息
即使找到了,也可能因为信息过载而理解错误
场景B:图书馆+索引系统(RAG)
先通过索引系统找到最相关的3-5本书
只需要专注阅读这几本书
注意力集中,理解深入
效率高,准确率高
这就是RAG的核心优势:不是让模型看更多,而是让模型看得更准。
5.2 BABILong实验的深层启示
让我们回顾BABILong论文的关键发现,并分析其背后的原因。
发现1:有效利用率仅10-20%
实验数据:
GPT-4 (128K窗口):有效利用约25K tokens
Claude 2.1 (200K窗口):有效利用约40K tokens
Gemini 1.5 (1M窗口):有效利用约200K tokens
背后原因:
位置偏差:模型更关注开头(primacy effect)和结尾(recency effect),中间部分容易被忽略
注意力衰减:距离越远的token,注意力权重越低
信息干扰:无关信息越多,关键信息越容易被"噪音"淹没
发现2:推理复杂度与准确率反比
实验任务及准确率(100K上下文):
背后原因:
每一步推理都需要准确的信息提取
错误会累积:第一步错误率15% × 第二步错误率15% = 总错误率27.75%
信息越分散,推理链越容易断裂
发现3:10K tokens是关键阈值
实验数据:
< 10K tokens:所有模型准确率 > 90%
10K - 50K tokens:准确率下降到70-80%
> 50K tokens:准确率下降到50-60%
> 100K tokens:准确率下降到30-40%
这个10K的阈值非常关键,它告诉我们:如果能把有效上下文控制在10K以内,就能保持高质量的推理能力。
而这正是RAG的设计目标!
5.3 RAG如何破解"大海捞针"
RAG通过三个核心机制,从根本上避免了"大海捞针"问题:
机制1:精准检索 - 只捞需要的"针"
传统长上下文:
输入:[整个大海] + 问题
模型:在10万条信息中寻找相关内容
结果:容易迷失,准确率低RAG方案:
步骤1:[向量检索] 问题 → 在10万条信息中找到最相关的Top-5
步骤2:[模型推理] 仅这5条信息 + 问题
结果:精准定位,准确率高技术细节:
使用语义向量(embeddings)表示所有知识
通过余弦相似度等指标快速检索
检索速度:毫秒级(即使在百万级数据中)
检索准确率:Top-5召回率通常 > 95%
机制2:上下文压缩 - 保持在有效范围内
设计原则:
将有效上下文控制在5K-10K tokens
远低于BABILong发现的10K阈值
确保模型能够充分利用所有输入信息
实际效果:
场景:客服问答
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
检索结果:
1. 用户订单信息 (500 tokens)
2. 商品详情 (1,000 tokens)
3. 保修政策 (800 tokens)
4. 售后流程 (600 tokens)
5. 常见问题 (500 tokens)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
总计:3,400 tokens(远低于10K阈值)
模型推理:
- 注意力集中
- 所有信息都高度相关
- 推理准确率 > 90%机制3:信息聚焦 - 减少干扰噪音
信噪比对比:
心理学支持:
人类认知研究表明,干扰信息越多,决策准确率越低
LLM的"认知"机制与人类类似
纯净的信息环境能显著提升推理质量
5.4 为什么RAG能够持续有效
即使未来LLM的长上下文能力继续提升,RAG的优势仍将存在,原因有三:
1. 信息论的基本原理
香农信息论告诉我们:信噪比决定信息传输质量
无关信息永远是"噪音"
减少噪音永远优于提升处理能力
2. 认知负荷理论
无论是人类还是AI,处理信息都有认知负荷上限
"看得多"不等于"理解得好"
精选信息永远优于海量信息
3. 经济学的边际效用递减
前10K tokens的价值最高
后续每增加10K,边际价值递减
在某个点之后,增加上下文反而降低效果
六、RAG的持续价值与未来
经过前面的分析,我们可以明确回答开篇的问题:即使LLM拥有无限上下文,RAG仍然不可或缺。
6.1 RAG的五大不可替代价值
1. 成本效益:降低28倍以上的推理成本
这不是小幅优化,而是数量级的差异:
年节省成本可达百万级
使得大规模商业应用成为可能
即使模型价格下降,比例优势依然存在
现实意义:
一个创业公司,用RAG方案月成本5000元可以支撑10万次调用
如果用长上下文方案,同样预算只能支撑3500次调用
这决定了业务能否规模化
2. 准确性保障:避免大海捞针困境
核心数据:
长上下文方案:多步推理准确率 < 50%
RAG方案:多步推理准确率 > 85%
差距:70%的相对提升
生产影响:
客服场景:准确率从50%提升到85%,意味着错误率从50%降到15%(降低70%)
医疗场景:准确率差异可能关乎生命
金融场景:准确率差异直接影响合规风险
3. 实时性:支持知识动态更新
长上下文方案的困境:
场景:电商促销活动
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
上午10点:双11活动开始,部分商品5折
问题:如何让LLM知道最新价格?
方案A:重新构建200K上下文
- 需要重新处理所有商品信息
- 耗时:数分钟
- 成本:每次更新都是完整的200K处理
- 不可行!
方案B:在prompt中说明"今天有活动"
- 模型不知道具体哪些商品打折
- 容易产生幻觉(hallucination)
- 准确率低RAG方案的优势:
场景:同样的促销活动
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
上午10点:更新向量数据库
- 只需更新变化的商品信息
- 耗时:秒级
- 成本:几乎可忽略
用户查询:实时检索到最新信息
- 自动获取最新价格
- 准确率高
- 无需任何额外操作4. 可控性:明确的信息来源和可追溯性
长上下文方案:
用户:"这款耳机的保修期是多久?"
模型:"保修期是12个月。"
用户:"你从哪里看到的?"
模型:"..." (无法追溯)RAG方案:
用户:"这款耳机的保修期是多久?"
系统检索:
- 文档ID: DOC_12345
- 来源:《售后政策2024版》第3.2条
- 原文:"所有音频产品享受12个月质保"
模型:"保修期是12个月。"
优势:
✅ 可以展示原文给用户
✅ 可以追溯信息来源
✅ 便于审计和合规
✅ 发现错误时可以快速定位和修复这在医疗、法律、金融等高风险领域尤其重要。
5. 可扩展性:知识库可以无限增长
长上下文的硬限制:
当前:200K tokens ≈ 15万字 ≈ 300页文档
问题:
- 企业知识库通常 > 10万页
- 即使有1M窗口,也装不下所有知识
- 窗口越大,效果越差(大海捞针)RAG的无限扩展:
当前:向量数据库可存储数十亿条记录
案例:
- Wikipedia:600万+文章
- 企业知识库:百万级文档
- 检索速度:毫秒级(即使在十亿级数据中)
关键:检索复杂度是 O(log n),而不是 O(n)6.2 最佳实践:何时用RAG,何时用长上下文
实际应用中,最佳策略往往是混合使用:
决策树
开始
↓
信息总量 < 10K tokens?
├─ 是 → 直接使用长上下文 ✅
└─ 否 ↓
↓
需要整体理解文档结构?
├─ 是 → 长上下文(如果<100K)✅
└─ 否 ↓
↓
需要实时更新?
├─ 是 → RAG ✅
└─ 否 ↓
↓
成本敏感?
├─ 是 → RAG ✅
└─ 否 ↓
↓
需要可追溯性?
├─ 是 → RAG ✅
└─ 否 → 长上下文 ⚠️典型场景推荐
混合架构示例
场景:智能法律助手
def legal_assistant(user_question):
"""
混合使用RAG和长上下文的法律助手
"""
# 步骤1:RAG检索相关法条和案例
relevant_docs = vector_search(
query=user_question,
top_k=5,
filters={"type": ["法条", "判例"]}
)
# 返回:5条最相关的法律文档,共约8K tokens
# 步骤2:判断是否需要深度分析某个文档
if needs_deep_analysis(relevant_docs):
# 使用长上下文深度分析单个文档
full_document = load_full_document(relevant_docs[0])
analysis = llm_analyze(
document=full_document, # 可能是50K tokens的完整判决书
question=user_question,
mode="deep_analysis"
)
else:
# 直接基于检索结果回答
analysis = llm_analyze(
documents=relevant_docs, # 8K tokens
question=user_question,
mode="quick_answer"
)
return analysis优势:
大部分情况下使用RAG(快速、便宜、准确)
需要时使用长上下文(深度分析)
两者优势互补
6.3 技术演进方向
RAG和长上下文不是对立的,而是共同演进的:
方向1:更智能的检索
当前RAG的局限:
基于语义相似度,可能遗漏隐含相关的信息
难以处理需要多跳推理的检索
未来方向:
HyDE (Hypothetical Document Embeddings):生成假设性答案,再用它来检索
查询重写:用LLM改写查询,提升检索准确率
迭代检索:根据初步答案,再次检索补充信息
# 传统RAG
query = "索尼耳机的降噪效果怎么样?"
docs = vector_search(query)
# 智能RAG
query = "索尼耳机的降噪效果怎么样?"
# 步骤1:生成假设性答案
hypothetical_answer = llm_generate(
"假设你要回答这个问题,答案可能包含哪些关键词?"
)
# 输出:"主动降噪、ANC技术、降噪深度、环境音模式..."
# 步骤2:用假设性答案检索
docs = vector_search(hypothetical_answer)
# 检索准确率提升20-30%方向2:RAG + 长上下文的深度融合
GraphRAG(Microsoft Research 2024):
将知识库构建为知识图谱
检索时不仅返回文档,还返回相关的图谱结构
将图谱和文档一起注入长上下文
效果:复杂推理准确率提升40%
传统RAG:
检索 → [文档1, 文档2, 文档3] → LLM
GraphRAG:
检索 → [文档1, 文档2, 文档3] + [知识图谱子图] → LLM
优势:
- 显式表达实体间关系
- 支持更复杂的推理
- 结合了结构化和非结构化知识方向3:Recurrent Transformers
问题:传统Transformer处理超长序列效率低
解决方案:Recurrent Transformers(如RWKV、Mamba)
将长序列分块处理
用循环机制传递信息
复杂度从 [O(n^2)] 降到 [O(n)]
与RAG的关系:
不是替代,而是互补
Recurrent Transformers处理单个长文档更高效
RAG处理多文档检索更精准
两者结合:用RAG检索,用Recurrent Transformers处理
方向4:多模态RAG
当前RAG:主要处理文本
未来RAG:
检索图片、视频、音频
跨模态检索:文本查询 → 返回图片+文本
多模态融合:综合多种信息源
场景:智能客服
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
用户:"这款手机的摄像头在哪个位置?"
传统RAG:
检索 → 文字描述:"后置三摄,左上角排列"
多模态RAG:
检索 → 产品图片 + 文字描述
LLM:[看图] + [读文字] → "如图所示,在手机背面左上角..."
优势:更直观,准确率更高6.4 给开发者的建议
如果你正在构建AI应用,以下是实用建议:
1. 默认选择RAG
除非满足以下条件,否则优先使用RAG:
信息总量 < 10K tokens
需要理解完整文档结构
一次性任务(不需要频繁调用)
2. 构建高质量的向量数据库
关键要素:
# 文档分块策略
chunk_size = 500 # tokens per chunk
chunk_overlap = 50 # 重叠部分,避免信息断裂
# 元数据设计
metadata = {
"source": "产品手册",
"category": "技术规格",
"date": "2024-10-01",
"product_id": "SKU12345"
}
# 混合检索
results = hybrid_search(
query=user_question,
vector_weight=0.7, # 语义检索权重
keyword_weight=0.3, # 关键词检索权重
filters=metadata_filters
)3. 监控和优化
关键指标:
检索准确率:Top-5召回率应 > 90%
端到端准确率:最终答案准确率应 > 85%
响应时间:检索 < 100ms,总响应 < 2s
成本:单次调用成本应 < 0.05元
A/B测试:
# 对比不同检索策略
strategy_a = vector_search(query, top_k=5)
strategy_b = hybrid_search(query, top_k=5)
# 评估哪个效果更好
evaluate_accuracy(strategy_a, test_set)
evaluate_accuracy(strategy_b, test_set)4. 准备好混合架构
架构设计:
class HybridLLMSystem:
def __init__(self):
self.vector_db = VectorDatabase()
self.llm = LLMClient()
def answer(self, question, context_size="auto"):
# 步骤1:评估任务类型
task_type = self.classify_task(question)
if task_type == "simple_retrieval":
# 使用RAG
docs = self.vector_db.search(question, top_k=3)
return self.llm.generate(question, context=docs)
elif task_type == "deep_analysis":
# 使用长上下文
full_doc = self.load_document(question)
return self.llm.generate(question, context=full_doc)
else: # complex_reasoning
# 混合使用
docs = self.vector_db.search(question, top_k=5)
enriched_context = self.enrich_with_graph(docs)
return self.llm.generate(question, context=enriched_context)七、结论
回到开篇的问题:LLM无限上下文了,RAG还有意义吗?
经过全面分析,答案是明确的:RAG不仅有意义,而且在可预见的未来都将是构建生产级AI应用的核心技术。
核心结论
1. 技术现实:长上下文的"虚标"可能依然存在
基于2024年的研究,顶级LLM仅有效利用10-20%的上下文窗口
超过10K tokens后,推理准确率显著下降
"大海捞针"实验揭示:窗口大≠能力强
需要特别说明的是:虽然GPT-5(400K)和Gemini 2.5 Pro(1M)等最新模型的完整测试数据尚未完全公开验证,但基于Transformer架构和注意力机制的固有特性,这些局限理论上依然可能存在。即使未来出现更长的窗口,这个问题也不太可能完全消失。
本文关于最新模型的性能推测仅供参考,实际表现需要等待更多独立的第三方测试验证。但从工程实践和成本效益的角度,RAG的价值依然显著。
2. 成本考量:28倍的差距
以Qwen-Max为例,在典型的AI客服场景中:
RAG方案年成本:6.1万元
长上下文方案年成本:174.6万元
节省成本:168.5万元
这不是小幅优化,而是数量级的差异。对于大多数企业来说,这决定了AI应用能否商业化。即使GPT-5和Gemini 2.5 Pro的长上下文能力有所提升,按token计费的模式下,成本优势依然会是RAG的核心竞争力。
3. 质量保证:精准检索 vs 大海捞针
基于已验证的研究数据:
长上下文多步推理准确率:< 50%
RAG多步推理准确率:> 85%
相对提升:70%
在医疗、法律、金融等高风险领域,这个准确率差异可能关乎生命、合规和财产安全。
4. 工程实践:RAG更易落地
实时更新:向量数据库秒级更新 vs 长上下文难以更新
可追溯性:明确的信息来源 vs 黑盒推理
可扩展性:知识库无限增长 vs 窗口硬限制
可维护性:问题定位容易 vs 调试困难
最终答案
LLM的超长上下文和RAG不是替代关系,而是互补关系。
长上下文:适合单文档深度分析、需要理解整体结构的任务
RAG:适合多文档检索、知识库问答、高频调用、成本敏感的场景
最佳实践:根据任务特点,灵活选择或混合使用
展望未来
未来的AI系统将是智能路由 + 混合架构:
用户问题
↓
[智能路由器]
↓
├─ 简单检索 → RAG → 快速回答
├─ 深度分析 → 长上下文 → 详细分析
└─ 复杂推理 → RAG + 长上下文 + 知识图谱 → 综合推理技术在演进,但核心原则不变:
精准优于海量:检索到的5K相关信息,优于200K的信息海洋
成本决定规模:只有成本可控,AI应用才能大规模落地
可控保证质量:可追溯、可验证的系统,才能用于生产环境
所以,不要被"无限上下文"的营销话术迷惑。在真实的生产环境中,RAG仍然是、也将继续是构建高质量AI应用的首选方案。
即使在2025年10月的今天,面对GPT-5的400K窗口和Gemini 2.5 Pro的1M窗口,这个结论依然成立。因为:
技术规律不会因窗口扩大而改变:注意力机制的固有局限、信息噪音的干扰、推理准确率的下降,这些都是架构层面的问题
经济规律更加稳固:按token计费的模式下,处理越多信息成本越高,这个比例关系不会变
工程实践的需求不变:实时更新、可追溯性、可维护性,这些都是生产系统的刚需
重要声明
本文基于2024年的学术研究和工程实践撰写,其中关于GPT-5(400K)和Gemini 2.5 Pro(1M)等2025年最新模型的性能分析,是基于已有研究规律的理论推测,尚未经过完整的独立第三方验证,仅供参考。
实际应用中,建议开发者:
关注官方发布的测试数据
进行自己的业务场景测试
基于实际效果和成本做出技术选型
优先考虑混合架构,而非单一方案
最后的建议:不要陷入"技术崇拜",认为最新、最大的就是最好的。真正优秀的工程师,会根据实际需求选择最合适的技术方案。在大多数情况下,一个设计良好的RAG系统,比盲目追求超长上下文要明智得多。
参考文献:
Greg Kamradt. "Needle in a Haystack - Pressure Testing LLMs". 2024.
BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack. NeurIPS 2024.
Anthropic. "Introducing Claude 2.1". 2023.
Microsoft Research. "GraphRAG: Unlocking LLM discovery on narrative private data". 2024.
如果这篇文章对你有帮助,欢迎点赞、收藏、转发。也欢迎在评论区分享你的知识经验,我们一起交流学习!
dtsola | IT解决方案架构师 I 一人公司实践者;专注一人公司、商业、技术、心理学、哲学内容分享。
服务:创业咨询 | IT咨询 | IT实施 | IT技术顾问服务
博客:https://www.dtsola.com
公众号:dtsola
#人工智能 #RAG #大模型 #ChatGPT #AI #AI技术 #AI应用 #AI工具 #AI降本增效 #机器学习